
Deployment Standards
In many technology deployments, speed is mistaken for competence. In a business where the calendar, phone, staff, clients, and revenue are connected, speed without verification is not efficiency. It is exposure.
Adaptiv Stratum treats deployment as a controlled operational event. Whether the business is large or small, the owner’s livelihood, the employee experience, and the client relationship all depend on systems that work correctly before they are trusted.
A salon, barbershop, spa, or appointment-based business does not have room for careless experimentation. The phone is not a sandbox. The calendar is not a beta environment. The first live interaction is a brand moment.
Reliable Deployment Begins With Respect for the Business
A service business is not just a set of tools. It is the owner’s income, the team’s workplace, the client’s trusted routine, and the reputation the business has built over years.
That is why Adaptiv Stratum approaches every deployment with caution, structure, and operational respect. We do not assume that technology should be activated simply because it is available. We first determine whether the system is understood, whether the rules are complete, whether the data is reliable, and whether the business is ready for the next stage.
The objective is not to move fast for the sake of appearing technical. The objective is to make careful changes that can be explained, tested, monitored, and reversed if necessary.
Why Deployments Fail
Automation and analytics rarely fail because the technology has no capability. They fail because assumptions reach real clients before they are tested.
Common failure points include:
- Service durations that do not match real execution time
- Buffers, cleanup time, or reset time that are not modeled correctly
- Deposit, cancellation, and reschedule rules that are loosely defined
- Complex service combinations that were not tested before launch
- Named-provider, VIP, or specialty requests that are not routed properly
- Calendar reads and writes that are not reconciled under pressure
- Staff workflows that change without sufficient training
- Escalation boundaries that are unclear
- No defined rollback plan when something behaves unexpectedly
In a premium service environment, small inconsistencies become visible quickly. A double booking, missed escalation, wrong service duration, or unclear handoff is not just a technical issue. It can become reputational damage.

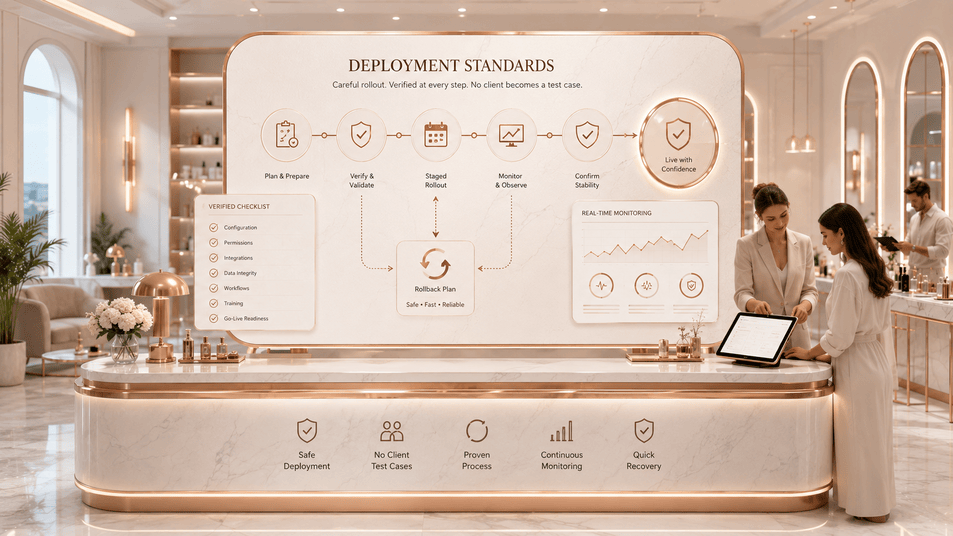
Our Deployment Standard
Every deployment is governed by a simple standard:
This standard applies whether we are supporting analytics, automation, AI phone handling, booking workflows, operational modernization, reporting logic, or integration work.
The system should not surprise the owner. The staff should not be left guessing. The client should not become the test case.
Primary Risk Categories
1. Calendar Integrity Risk
Availability must reflect real operating behavior, not just technical availability. Service timing, buffers, provider capacity, cleanup time, closing boundaries, and staff-specific limitations must be accounted for before booking logic is trusted.
2. Client Experience Risk
A system may be technically correct but still feel wrong to the client. Tone, timing, clarity, policy explanation, escalation behavior, and brand fit must be reviewed before live exposure.
3. Policy Consistency Risk
Deposits, cancellation windows, reschedule rules, pricing boundaries, and exceptions must produce consistent outcomes. Inconsistency creates confusion for staff and erodes trust with clients.
4. Data Integrity Risk
Analytics and automation depend on accurate source data. If service names, durations, staff assignments, client records, or transaction mappings are inconsistent, the output can appear precise while being operationally misleading.
5. Staff Adoption Risk
A system that the team does not understand will not be used correctly. Deployment includes explanation, training, and workflow confirmation so staff know what changed and what they are expected to do.
6. Escalation Discipline Risk
Undefined escalation boundaries force improvisation. Improvisation is not compatible with a premium client experience. The system must know when to proceed, when to pause, and when to involve a human.
7. Business Continuity Risk
The business must remain operational during transition. A deployment plan must include fallback processes, access controls, support contacts, monitoring, and rollback steps before changes are introduced.

Verification Before Exposure
Activation is not a technical toggle. It is a reputational event.
Before any live interaction occurs, Adaptiv Stratum performs structured validation based on the service being deployed.
1. Policy Capture and Constraint Mapping
- Service catalog reviewed against real business behavior
- Service durations validated against actual execution time
- Buffers, cleanup time, and reset time documented
- Deposit and cancellation rules defined precisely
- Reschedule and modification rules confirmed
- Named-provider and specialty-service rules documented
- Escalation triggers identified before launch
- Owner assumptions confirmed before implementation
2. Data and Configuration Review
- Source systems reviewed for completeness and consistency
- Service names checked for duplicates or ambiguity
- Staff assignments and permissions reviewed
- Calendar structure reviewed against operational reality
- Reporting fields evaluated for reliability
- Known data gaps documented before analysis or automation
3. Calendar Reconciliation
- Live availability cross-checked against expected business rules
- Conflict scenarios modeled across high-demand periods
- Double-book prevention verified where supported
- Booking writes confirmed against the source calendar
- Metadata, service, provider, and time fields validated after test bookings
- Failure cases tested to confirm safe stop or escalation behavior
4. Client Communication Review
- Greeting, tone, and brand language reviewed
- Policy explanations tested for clarity
- Boundary language confirmed for deposits, pricing, and cancellations
- Sensitive or high-touch scenarios routed appropriately
- Handoff summaries reviewed for usefulness to staff
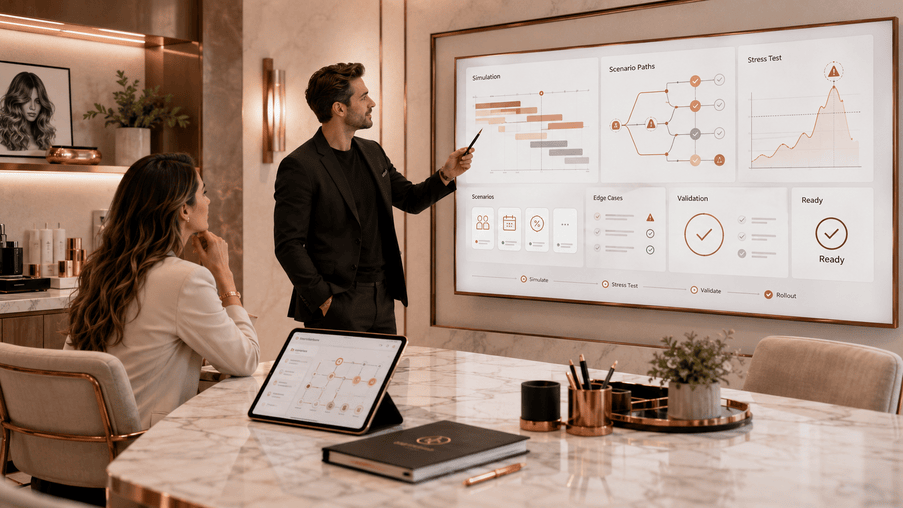
Simulation and Stress Modeling
Systems usually appear stable during simple flows. Problems appear during compression, ambiguity, exceptions, and timing pressure.
Simulation is designed to expose those conditions before clients encounter them.
Structured Booking Simulation
- Single-service bookings across multiple providers
- Multi-service sequences requiring coordinated time blocks
- Bookings near opening and closing boundaries
- After-hours intake with calendar write verification
- Requests involving preferred staff or restricted services
- Reschedules, cancellations, and modification requests
Peak Density Modeling
- Back-to-back scheduling across providers
- Simultaneous booking attempts within the same window
- Compressed schedules with limited open capacity
- Overflow routing when availability thresholds are reached
- Rapid changes during busy operating periods
Edge Case Injection
- Ambiguous service descriptions
- Mixed-duration service combinations
- Consultation-required services
- Clients asking for exceptions to policy
- Boundary time requests
- High-touch or VIP requests
- Incomplete information from the caller or client
Post-Simulation Reconciliation
Every simulation is reconciled against the intended outcome.
- Requested service parameters
- Applied duration and buffer logic
- Assigned provider routing
- Final written calendar entry
- Policy language used during the interaction
- Escalation decision, where applicable
- System behavior during failure or uncertainty

Rollback Planning at Every Stage
A responsible deployment does not rely on hope. Every meaningful change should have a way to pause, reverse, isolate, or return to a known working state.
Rollback planning is not a sign of uncertainty. It is a sign of operational discipline.
What Rollback Planning May Include
- Documented pre-change configuration
- Clear record of what was changed and when
- Known fallback workflow if automation is paused
- Manual booking or staff-handled process if needed
- Temporary suspension of a feature without disrupting the entire system
- Owner and staff notification steps
- Recovery review to identify root cause before reactivation
Escalation Discipline
Automation should not attempt universal resolution. Execution must be separated from interpretation.
- Availability is read directly from the source system where supported.
- Bookings are written only within defined constraints.
- Durations are fixed to configured parameters.
- Policy rules are enforced consistently.
- Unclear requests are escalated instead of guessed.
- Partial confirmations are avoided.
- Speculative availability is not treated as confirmed availability.
If confirmation cannot be achieved, the interaction escalates. No speculative booking. No partial confirmation. No inferred availability.
Defined Human Transfer Conditions
- Consultation-required services
- Requests outside normal booking patterns
- High-touch or VIP interactions
- Ambiguous or conflicting service descriptions
- Policy exceptions requiring owner or staff judgment
- Client complaints or sensitive situations
- System uncertainty, API failure, or incomplete confirmation
Owner Sign-Off and Controlled Rollout
No activation proceeds without owner review and documented approval.
- Booking rules reviewed and confirmed
- Service mappings validated
- Policy enforcement demonstrated
- Escalation triggers tested
- Fallback process reviewed
- Rollback plan confirmed
- Monitoring approach defined
Phase One: Internal Review
Rules, workflows, configuration, and sample outputs are reviewed before any live client exposure.
Phase Two: Controlled Test Activity
Structured test scenarios are performed to confirm expected behavior, identify edge cases, and refine logic before activation.
Phase Three: Limited Activation
Deployment may begin in a limited context, such as after-hours coverage, selected workflows, or monitored use cases where operational pressure is lower.
Phase Four: Progressive Expansion
Only after stability is demonstrated does the deployment expand to additional workflows, higher-volume periods, or more complex use cases.
Phase Five: Post-Launch Review
After activation, results are reviewed to confirm that the system is behaving as intended and that staff understand how to use or respond to it.
Monitoring After Launch
A deployment is not complete the moment it goes live. The first days of operation are reviewed carefully because real-world usage reveals patterns that testing cannot always reproduce.
Depending on the engagement, post-launch monitoring may include:
- Review of completed bookings or workflow outcomes
- Review of failed, paused, or escalated interactions
- Calendar reconciliation after live activity
- Staff feedback review
- Client communication review where appropriate
- Adjustment of rules, scripts, timing, routing, or reporting logic
The purpose of monitoring is to confirm stability, not to leave the owner responsible for discovering issues alone.
What This Protects
Deployment discipline protects more than technology. It protects the business itself.
- The owner: by reducing avoidable operational surprises
- The staff: by preventing confusing systems from disrupting daily work
- The calendar: by protecting availability, timing, and provider capacity
- The client experience: by keeping communication accurate and composed
- The brand: by ensuring technology reinforces the standard of service
- The revenue engine: by preventing avoidable leakage, missed handoffs, and booking confusion
A careful deployment may appear slower at the beginning, but it prevents the expensive problems that rushed deployments create later.
Proof Before Exposure
Premium brands depend on predictability. Clients expect accurate scheduling, consistent communication, and seamless execution. Technology must reinforce that expectation.
Adaptiv Stratum deploys with caution because your business is not abstract. It is your livelihood, your team’s workplace, and your client’s experience. The standard is not speed alone. The standard is controlled, verified, explainable progress.
Request a Deployment Review
If your business is considering automation, analytics, modernization, or operational technology changes, the safest first step is a structured review.
We will assess the current operating model, identify risk areas, determine readiness, and define what should be verified before anything is exposed to clients.